Web上から画像を収集(スクレイピング)するスクリプトを書いた
機械学習などで画像を収集したいことがある。
学習用の画像は、買ったり、自分で撮影したり、公開されているデータセットを使ったり、インターネットから拾ってきたり、と様々な方法で入手可能である。
今回はインターネットから画像を拾ってくるスクリプトを書いたのでそれの記録を残す。
なお、ここで示すのスクリプトや規約は記事投稿時点での内容となっている。そこからWebサイトの仕様や規約が変わっていなければそのまま使えるはずである。(仕様は結構変わるのでその都度変更が必要になる。)
概要
画像検索サービスにはGoogle, Bing, Twitterなど様々なものがあるが、規約的にだめだったり、検索ページがJSなどで動的に生成されて技術的にスクレイピングが難しかったり、APIの利用制限があったりするサイトが多い。
今回は、規約上問題なさそう(駄目とは明記されていない)でかつ簡単にスクレイピングが可能そうなYahoo!検索(画像)の簡易版を使った。
キーワードをYahoo!画像検索に渡し、HTMLをお馴染みのRubyのNokogiriを使ってパースしてimgのsrcのURLを取得し、画像をダウンロードして保存する。
Yahoo!画像検索の簡易版を用いる理由は表示がページネーションしてあり、URLの変更だけで次の画像を読み込むことができるからである。
Yahoo!画像検索の簡易版のURLの構造は次のようになっている。
https://search.yahoo.co.jp/image/search?p=#{keyword}&rkf=1&oq=&dim=&ctype=photo&imc=&ei=UTF-8&xargs=7&b=#{number}#{keyword}には検索ワード、#{number}にはページ先頭の画像のインデックスが入っていると思われる。Yahoo!画像検索の簡易版では1ページに20枚の画像が出てくるので、
#{number}は20n+1の値を入れる。例えば、”メタルスライム”の最初の1ページのURLは”https://search.yahoo.co.jp/image/search?p=メタルスライム&rkf=1&oq=&dim=&ctype=photo&imc=&ei=UTF-8&xargs=7&b=1“となる。
ここから、Webブラウザの開発ツールを使って、画像のURLを取得する。
Nokogiriの使用方法やWeb開発ツールの使い方・見方はここを参照。
これによって、idがgridlist(
#gridlist)のimgタグのsrc属性に画像のURLがあることがわかる。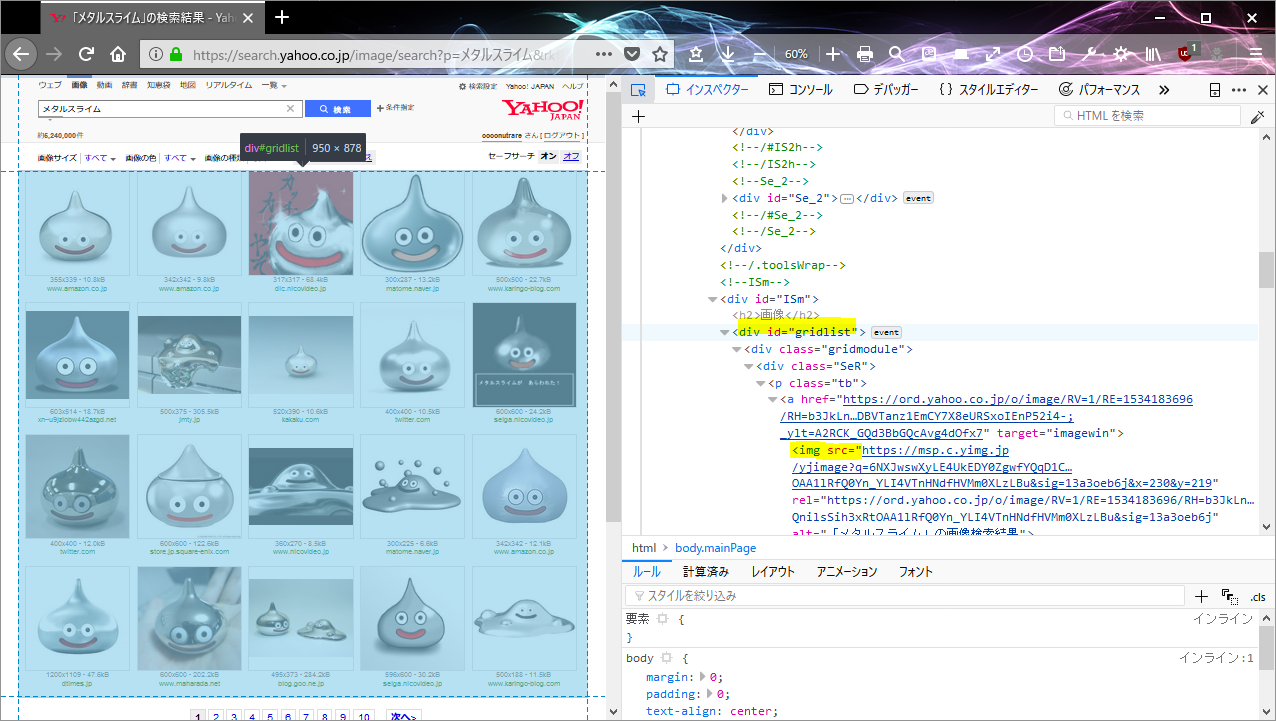
あとはこのページ全体の#gridlist内の画像のURLを取得し、そこからダウンロードし、次のページ(URLの#{number}を20増やす)でもそれを繰り返すだけで、大量の画像が手に入る。
コード
コードのサンプルを以下に示す。
なおこのサンプルを動かすためにはRubyとそのgemであるNokogiriが必要である。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
require "nokogiri" require "open-uri" require "fileutils" # 指定したページの検索用URLを作成 # 1ページで20枚ほどある def get_search_url(keyword,page) return URI::parse(URI::encode("https://search.yahoo.co.jp/image/search?p=#{keyword}&rkf=1&oq=&dim=&ctype=photo&imc=&ei=UTF-8&xargs=7&b=#{(page-1)*20+1}")) end # 画像のURLの一覧を取得 def get_img_url(search_url) html=Nokogiri::HTML(open(search_url)) imgs=[] html.css("#gridlist").css("img").each do |img| imgs.push(img["src"]) end return imgs.size==0 ? nil : imgs end # 画像を保存 def save_img(urls,path,index) urls.each_with_index do |url| begin open("#{path}/#{index}.jpg","wb") do |f| open(url) do |data| f.write(data.read) end print("\r合計#{index+1}枚保存しました") end index+=1 rescue next end end return index end # 指定の枚数以上集める def run(keyword,path,n,start_page=1) index=0 # 指定パスフォルダがなければ作成 unless File::exist?(path) then FileUtils::mkdir_p(path) end p=start_page loop do arr=get_img_url(get_search_url(keyword,p)) if arr then # arrがnilではない(画像がある場合) index=save_img(arr,path,index) if index>n then puts("\n目標枚数を達成しました。終了します。") break end else # 画像がもうなければarrはnilになる puts("\nこれ以上画像が取得できませんでした。終了します。") break end sleep(0.5) # サーバーの負荷を減らすため p+=1 end puts("\n取得ページ: #{start_page}-#{p}") return index end # プログラム開始 if ARGV.size!=3 then puts("引数が足りません\n使い方: ruby #{__FILE__} [キーワード] [保存先ディレクトリパス] [目標枚数]") exit end keyword=ARGV[0] path=ARGV[1] n=ARGV[2].to_i puts("キーワード: #{keyword}\n保存先: #{path}\n目標枚数: #{n}") run(keyword,path,n) puts("\n完了") |
5-9行目はキーワードとページを渡すと検索用のURLを生成する。
11-19行目は検索用URLから#gridlistのimgタグのsrc属性を返す。画像が取得できないときにはnilを返す。
21-37行目は画像のURLの配列を受け取りそれを順に開いてダウンロードする。その際、ファイル名は連番でつけている。なお、ここでは拡張子を強制的にjpgにしているがこれはダウンロードされる画像の形式がわからないので仮でつけている。
39-65行目はこれらの一連の流れをパージごとに繰り返す。最初に指定されたパスのディレクトリがなければ作成し、1ページ目から画像をダウンロードしていく。これを指定された画像枚数を超えるまで繰り返す。各ページ取得の間には0.5秒のスリープを入れて相手サーバーへの負荷を少し減らしている。
67-77行目がコマンドライン引数からキーワードや保存先パス、目標枚数などを取得して実際に処理を回している。
なお、このコードは以下のボタンからダウンロードできる。
ソースコードを見れば使い方はわかると思うが、
ruby crawler.rb キーワード 保存先ディレクトリ名 目標枚数で実行できる。例えば、メタルスライムをslimeフォルダに50枚以上集めたいときには、
ruby crawler.rb メタルスライム slime 50となる。フォルダ名はなければ自動的に生成される。目標枚数は1ページ単位で超えたかどうかをチェックするため、最大で+19枚ほど保存される場合がある。
実行例
メタルスライムをslimeフォルダに30枚以上集めたいときのコマンド(ruby crawler.rb メタルスライム slime 30)の実行例を見てみる。
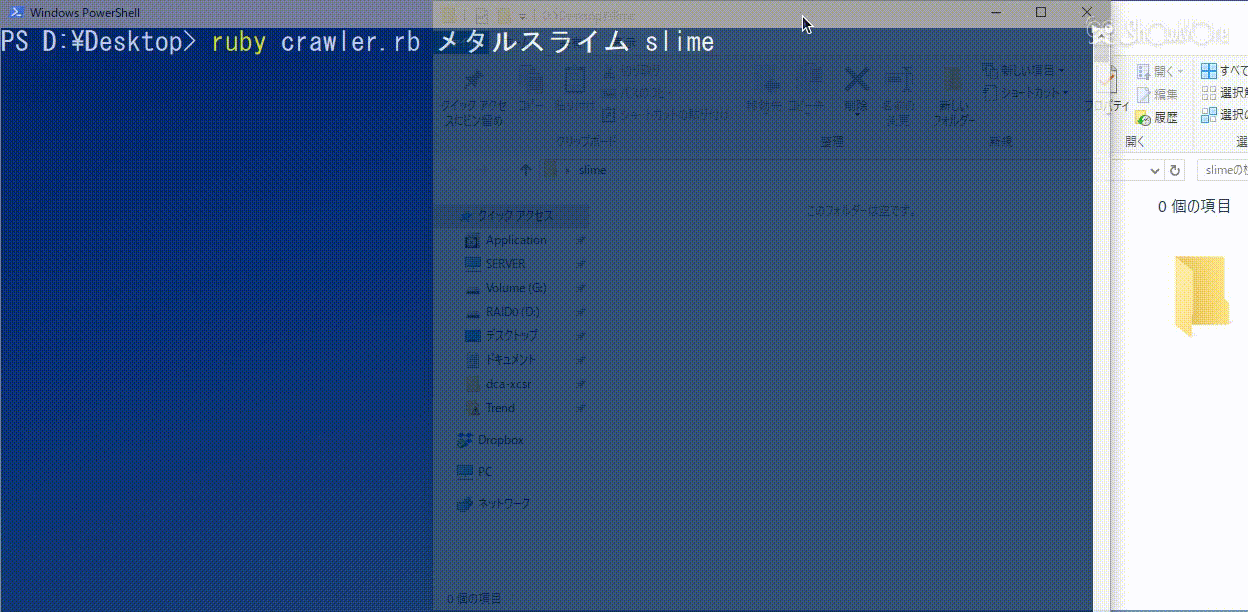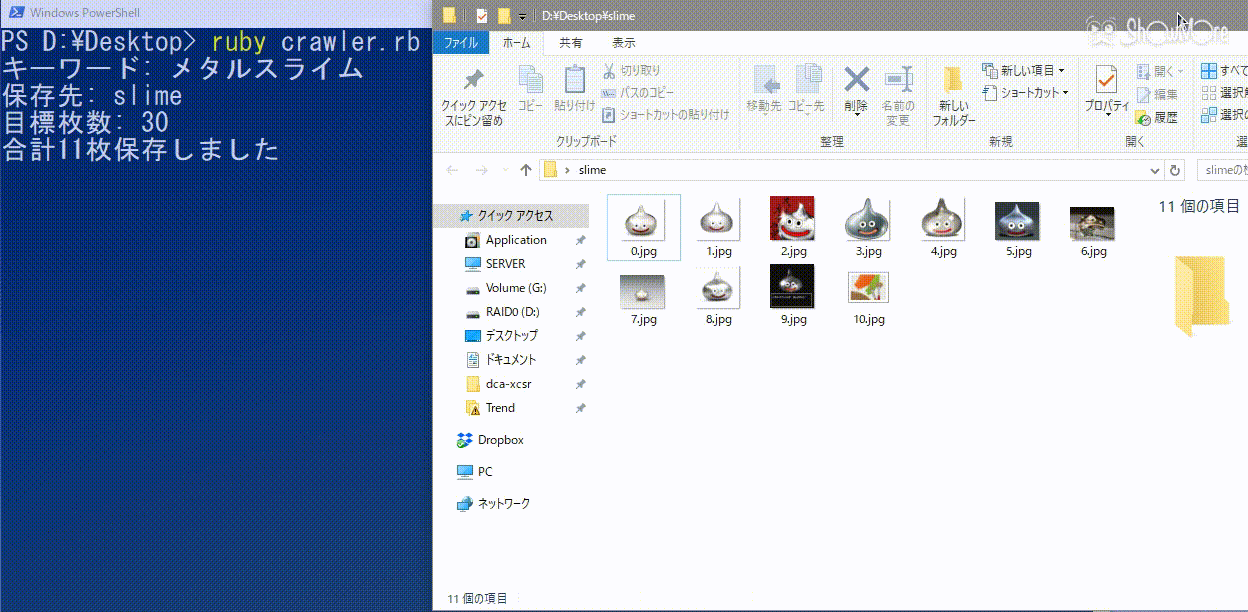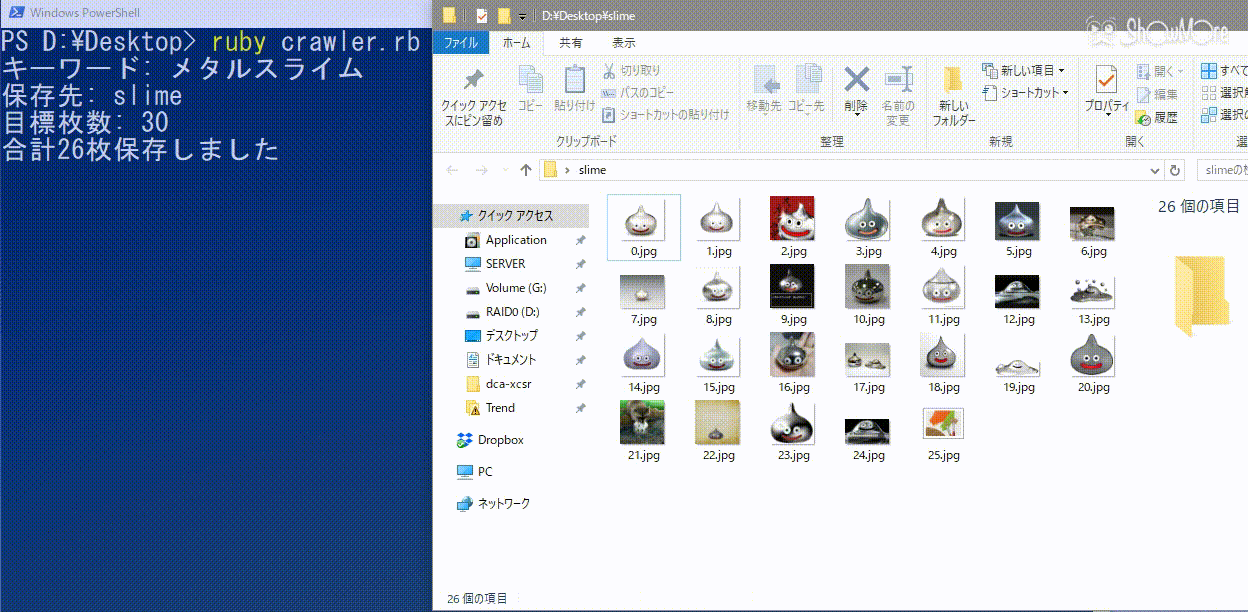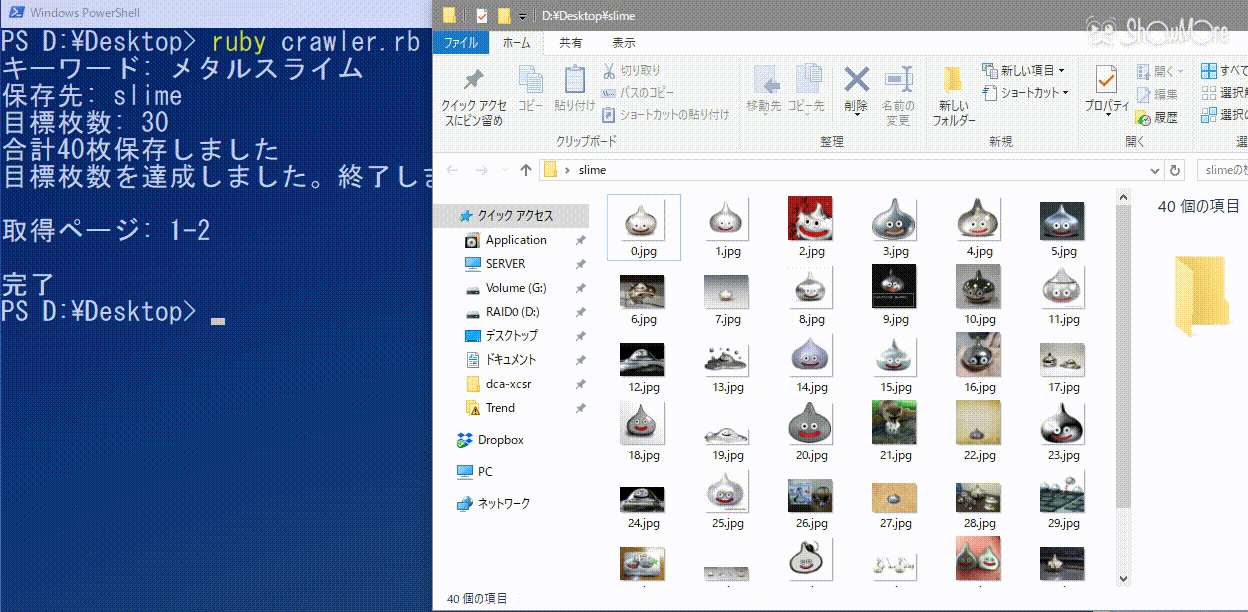
きちんと画像が保存されている事がわかる。
注意
このスクリプトはきちんと節度を守って利用してほしい(本来はAPIなどを利用するべきである)。
また、サイトの仕様が変わるとそのままでは利用できないので、何かしらの手を加える必要があるので注意。
Yahoo!の規約は変わるかもしれないのでチェックしてから利用するべし。
検索の精度はYahooに依存するが、ぜんぜん違う画像が出てくる可能性も十分にあるので保存される画像を利用する前にチェックするべし。
同じカテゴリー(技術メモ)の他の記事を表示
全記事を表示
タグ: Ruby, Web