強化学習の1つであるQ学習のWindows用のデモプログラムです。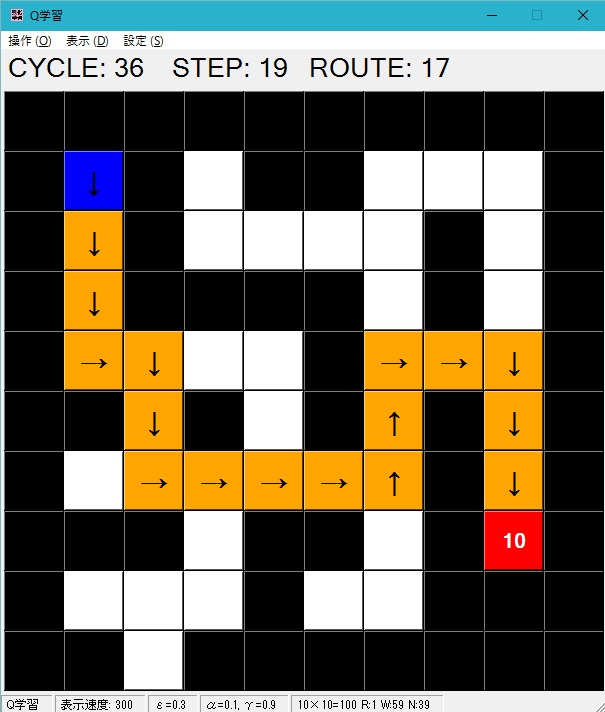
迷路の構造と報酬を決定し、エージェントが迷路問題を学習する様子が見れます。
迷路の構造や報酬値はいつでも変更でき、リアルタイムに反映されます。
Q学習の他にも報酬値が一定のProfit Sharingが実装してあります。
なお、Q学習や強化学習の解説はここでは行いません。各自で調べてください。
ダウンロードとインストール
このプログラムはWindows7以上の64bit OSで動作確認をしています。
ダウンロード
実行ファイルのみとインストーラー形式の2種類用意しました。
実行ファイルのみの方は.NET Framework(4以上)がインストールされている必要があります。
インストーラー形式の場合は.NET Frameworkが入っていない場合は自動的にインストールされます。
よくわからない方はインストーラー形式をお勧めします。
インストールと実行方法
実行ファイルの場合
ダウンロードした「ReinforcementLearning.exe」を好きな場所に保存しダブルクリックして実行します。
.NET Framework(4以上)の環境がない場合は実行できませんので、インストーラー形式のダウンロードをするか、.NET Frameworkをインストールしてください。
インストーラー形式の場合
ダウンロードした「ReinforcementLearning.zip」を適当な場所に解凍します。
解凍した先にある「setup.exe」を実行することでインストールすることが出来ます。
.NET Framework(4以上)がインストールされていない場合はこの時にインストールされます。(その場合はインターネットに接続されている必要があります。)
インストールが完了するとスタートメニューに「ReinforcementLearing」が追加されます。
これを選択することで実行することが出来ます。
インストールが完了したら、「ReinforcementLearning.zip」及び「ReinforcementLearning.zip」を解凍したフォルダとその中身は削除可能です。
アンインストール
実行ファイルの場合
「ReinforcementLearning.exe」を削除してください。
インストーラー形式の場合
コントロールパネルの「プログラムと機能」から「ReinforcementLearning」を探し、ダブルクリックし、OKを押します。
使い方
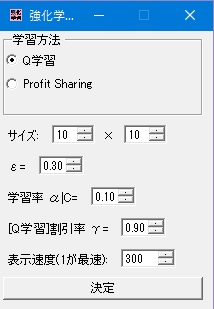
- プログラムを立ち上げると設定画面が現れます。
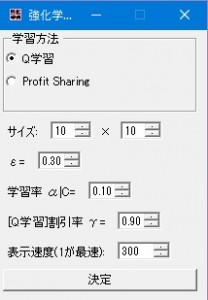
- 学習方法は「Q学習」または「Profit Sharing」から選択します。
- サイズは迷路の大きさです。大きくし過ぎると画面に入りきれなかったり、学習に時間がかかったりしてしまいます。
- εはランダムに行動する確率です。0にすると新たな道を探索しなくなるため値を0.1~0.7あたりを設定したほうが良いです。学習中に変更することが可能です。
- 学習率α(Q学習)/C(Profit Sharing)は学習のパラメーターです。0にすると学習しなくなります。学習中に変更することが可能です。
- 割引率γはQ学習のパラメーターです。学習中に変更することが可能です。
- 表示速度は画面の更新速度です。小さいほど速く学習が終わります。学習中に変更することが可能です。
設定が完了したら、「決定」ボタンを押します。
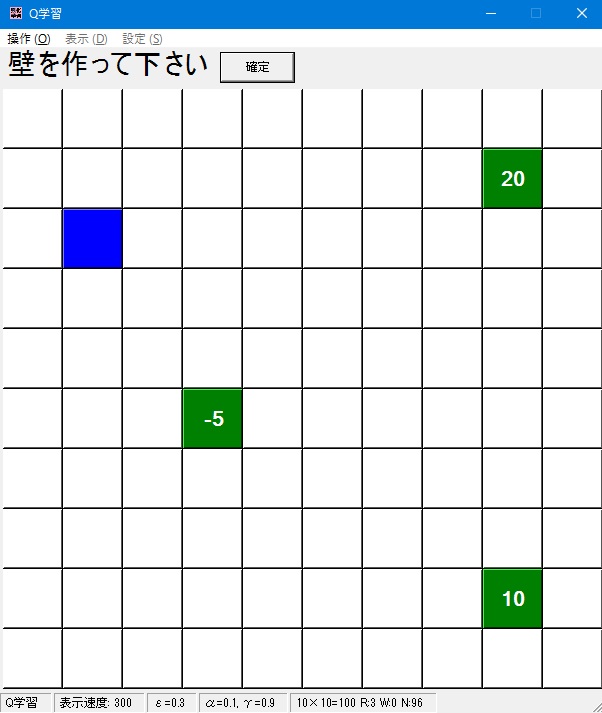
- スタート地点を決めます。(後で変更することも出来ます。)
エージェントのスタート地点にしたいところをクリックします。
クリックするとマス目が青くなります。

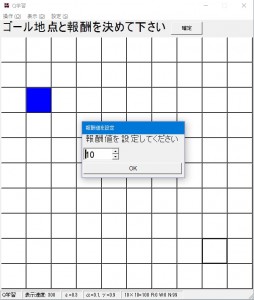
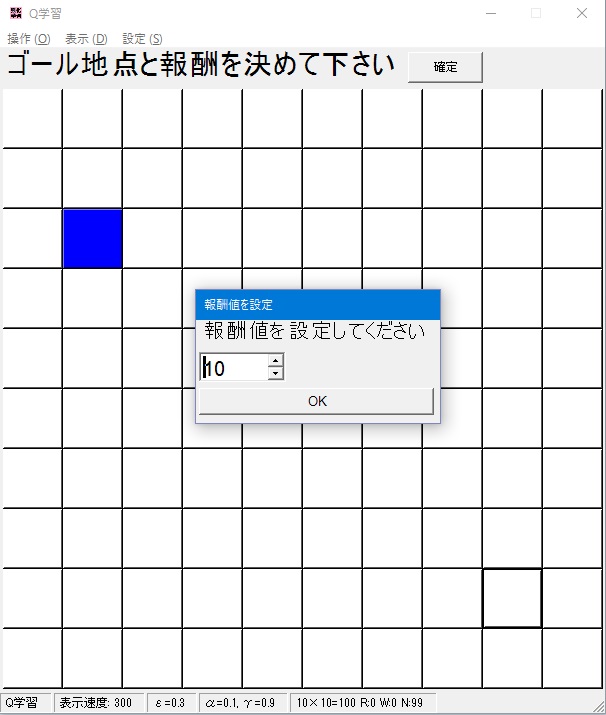
- ゴール地点とそこにたどり着いた際の報酬値を決めます。ゴール地点は複数設置出来ます。(後で変更することが出来ます。)
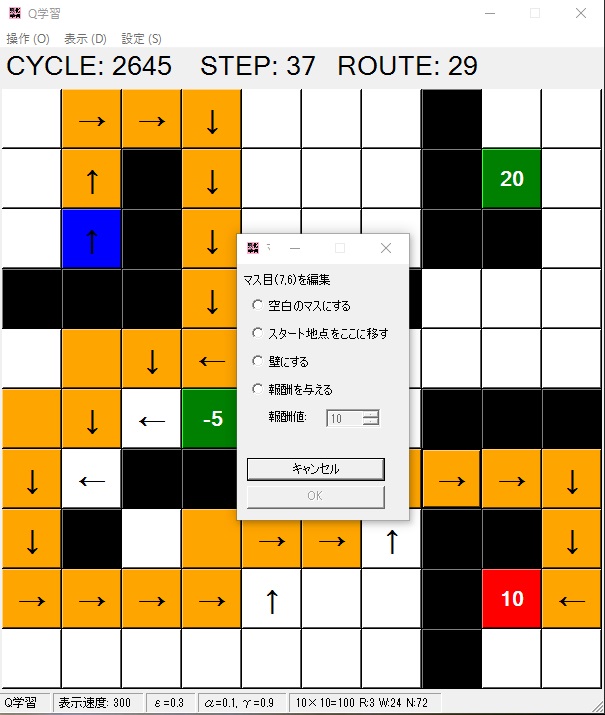
ゴールを設置したい場所をクリックし、出てきたダイアログで報酬値を決め、OKを押します。報酬値は負の数でも実数値でも可能です。
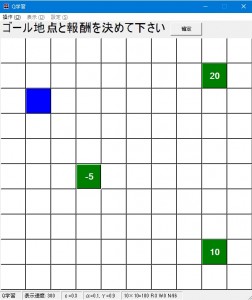
OKを押すとそのマスが緑になり、そこに白地で報酬値が表示されます。
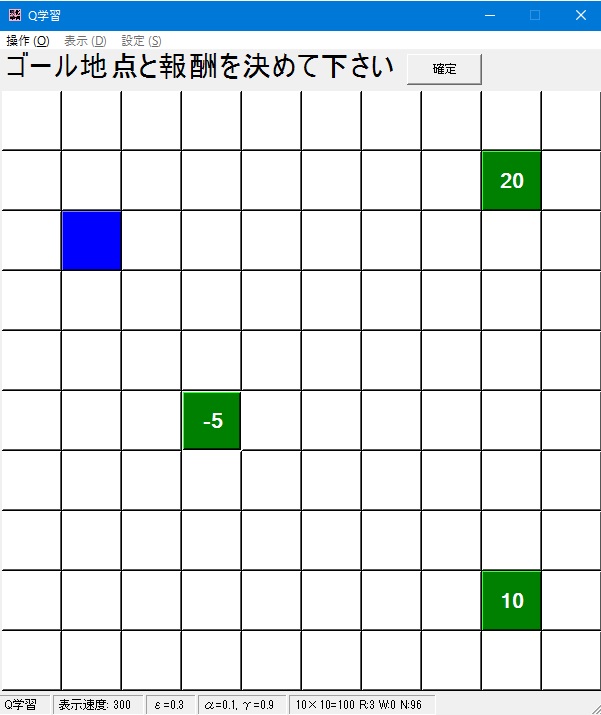
これを繰り返し、ゴールを複数設定することが出来ます。
なお、誤ったマス・報酬値を設定してしまった場合そのマスをクリックすることで取り消すことが出来ます。
ゴール地点の設定が終わったら右上の「確定」ボタンを押します。


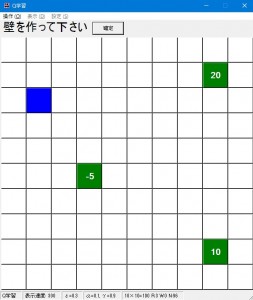
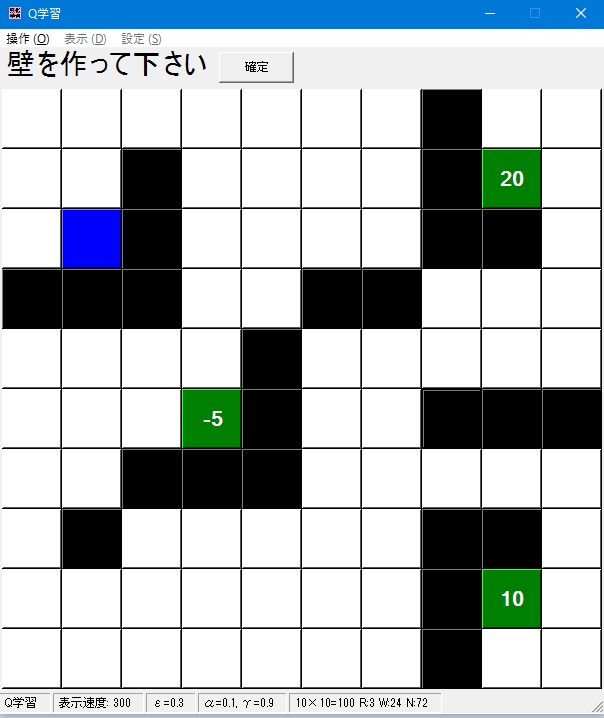
- 壁を作ります。壁がある方向にエージェントは進めなくなります。(後で変更することが出来ます。)
壁を作りたいところをクリックすると黒くなり、壁になります。これを繰り返します。
壁を消したい場合はもう一度クリックします。壁は無くても構いません。
壁を作ったら上の「確定」ボタンを押します。
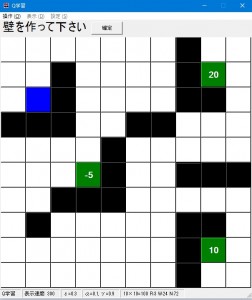
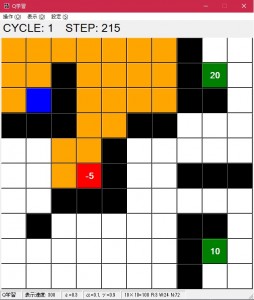
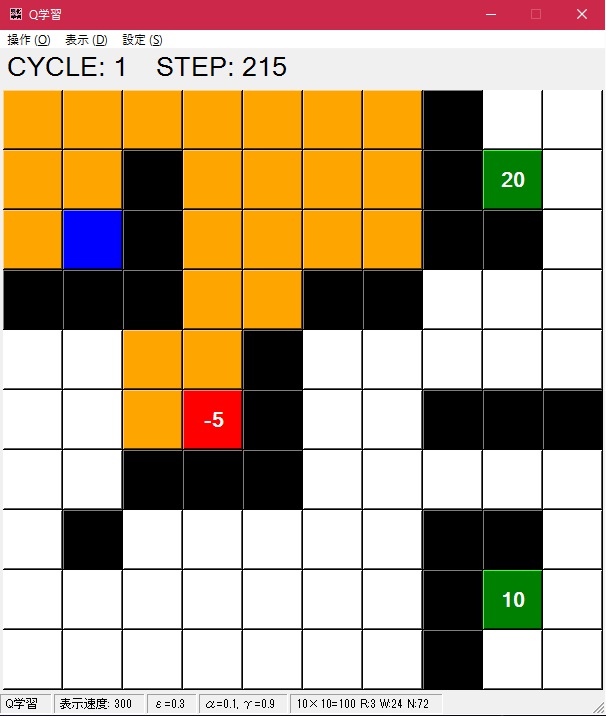
- 「操作」メニューの「次へ」を押すと実際に学習が始まります。次へを押すたびに次のサイクルに進みます。1サイクルはいずれかのゴールに到達するかステップ上限に行くまで行われます。
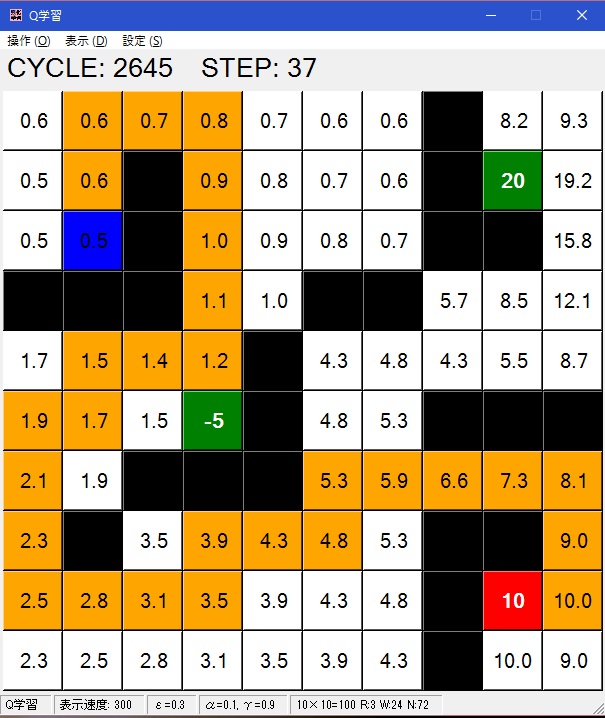
上の「CYCLE」が現在のサイクル、「STEP」がそのサイクルでのゴールまでのステップ数です。オレンジのマス目がスタートからゴールへの軌跡を示しており、赤いマスがゴールしたマスです。
「操作」メニューの「学習開始」を押すとエンドレスにサイクルが回ります。「一時停止」を押すことで一時的に止めることが出来ます。

- 「操作」メニューの「アプリケーションの終了」でプログラムを終了します。
「リセット」で設定からやり直すことが出来ます。
「同じ条件でやり直す」は設定や迷路の環境はそのままでQ値を0にリセットして学習し直します。




機能
表示方法
このプログラムは次の4つからプログラムの表示方法を選ぶことが出来ます。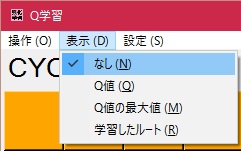
- なし
- Q値
- Q値の最大値
- 学習したルート
これらは表示メニューからリアルタイムに変更できます。
デフォルトは「なし」になっています。
なし
マス目にどの情報も書かれていない状態です。
Q値
4方へのQ値が表示されます。

Q値の最大値
4方へのQ値のうちの最大値が表示されます。
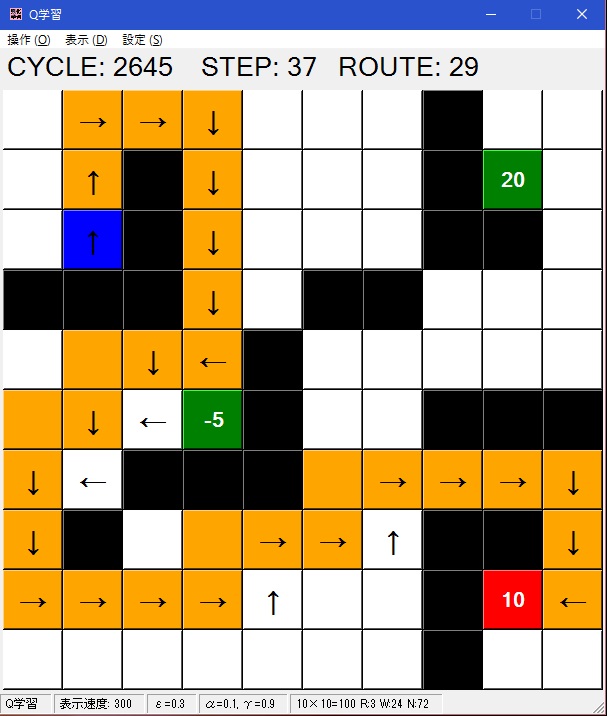
学習したルート
Q値が最も高いマスへ進んだ場合の道筋が矢印で表示されます。
また、表示部の「ROUTE」にそのルートのステップ数が記載されます。
リアルタイムな環境変化
マス目をクリックすることによりいつでもそのマスの役割を変更することが出来ます。
これにより報酬値を突然負にしたり、学習したルートを壁で塞ぐ、スタートの位置を変えるなど様々な変更が可能です。
リアルタイムなパラメーター変更
「設定」メニューからパラメーターをいつでも変更可能です。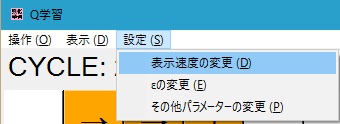
設定の変更が可能な項目は次のとおりです。
- 表示速度
1サイクルあたりの表示時間を設定できます。小さいほど早くなります。 - ε(ランダム行動率)
- その他のパラメーター
学習率や割引率が変更できます。
パラメーターは変更した次のサイクルから有効になります。
注意
- タブレットモードでは上手く動きません。
- このプログラムによって生じたいかなる損害に対して作者は責任を負いません。